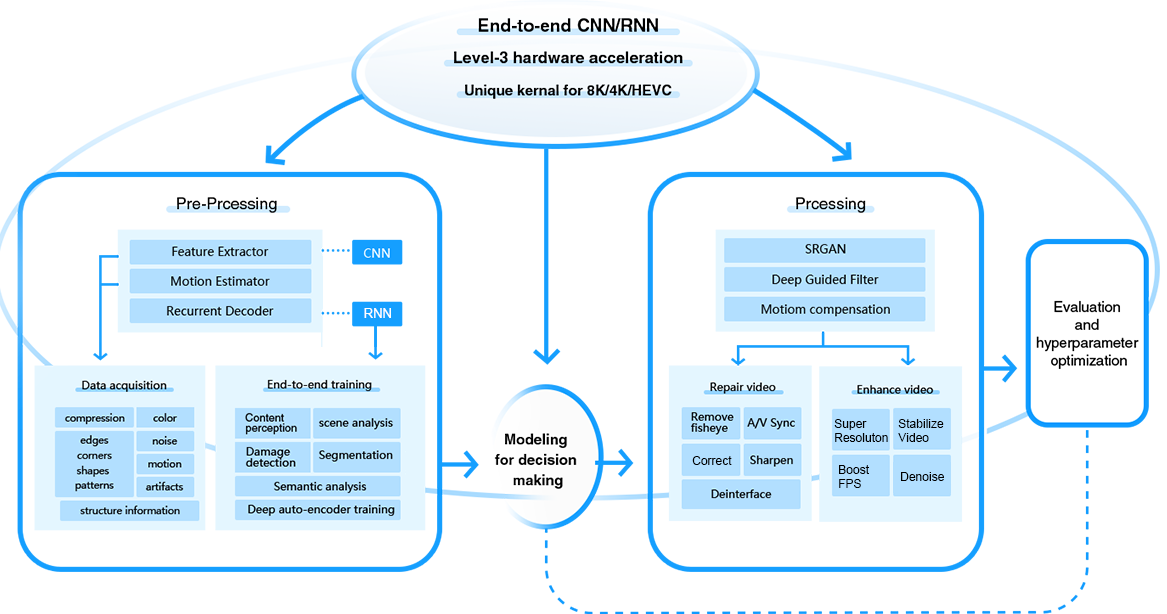
Codificatore di estrazione di funzionalità: un'architettura di rete neurale convoluzionale (CNN) estrae abilmente bordi, forme, trame, informazioni strutturali, rumore, luminosità, artefatti di compressione, movimento e altro ancora. Raccogliendo queste funzionalità dal suo set di dati, il modello viene addestrato a distinguere una qualità video superiore.
Decoder ricorrente: questa struttura di autoapprendimento, integrata con la rete neurale ricorrente (RNN), si impegna nell'analisi iterativa all'interno di un flusso video. L'analisi della scena, il riconoscimento del contenuto, la segmentazione semantica, la classificazione e altre operazioni facilitano l'identificazione delle informazioni essenziali, perfezionando ulteriormente la comprensione del modello.
Deep Guided Filter (DGF): il modulo accerta l'intricata relazione di mappatura tra la guida e i video di input. Le correlazioni spaziali e i dati strutturali vengono fusi dalle immagini di riferimento per preservare i dettagli e i bordi dell'immagine, culminando in un output denoizzato e migliorato.
SRGAN: utilizzando una rete neurale a doppio componente, SRGAN sovracampiona la risoluzione video attraverso l'architettura a blocchi residui. La formazione contraddittoria con un modello discriminatore valuta la qualità rispetto alle controparti effettive ad alta risoluzione, creando progressivamente risultati notevoli attraverso la fusione di reti generative contraddittorie e perdita percettiva.
MEMC: tiene traccia dei fotogrammi adiacenti all'interno di un video per dedurre la complessa traiettoria di movimento di oggetti dinamici, come traslazione, rotazione e ridimensionamento. Ciò consente di contestualizzare l'ottimizzazione del video. In base alla stima del movimento, la successiva compensazione del movimento rettifica l'allineamento di ciascun fotogramma facendo corrispondere il fotogramma precedente con quello corrente, in modo da contrastare gli effettivi offset indotti dal movimento. Ciò riduce problemi come jitter, sfocatura e discontinuità dei fotogrammi, creando in definitiva un video di maggiore stabilità, fluidità e lucidità cristallina.













 Super Risoluzione AI
Super Risoluzione AI Stabilizzazione Video AI
Stabilizzazione Video AI Interpolazione dei Frame AI
Interpolazione dei Frame AI























 Risoluzione
Risoluzione Frequenza fotogrammi
Frequenza fotogrammi Bitrate
Bitrate Profondità colore
Profondità colore Metodi di codifica
Metodi di codifica Luminosità
Luminosità Gamma di colori
Gamma di colori Post-produzione
Post-produzione