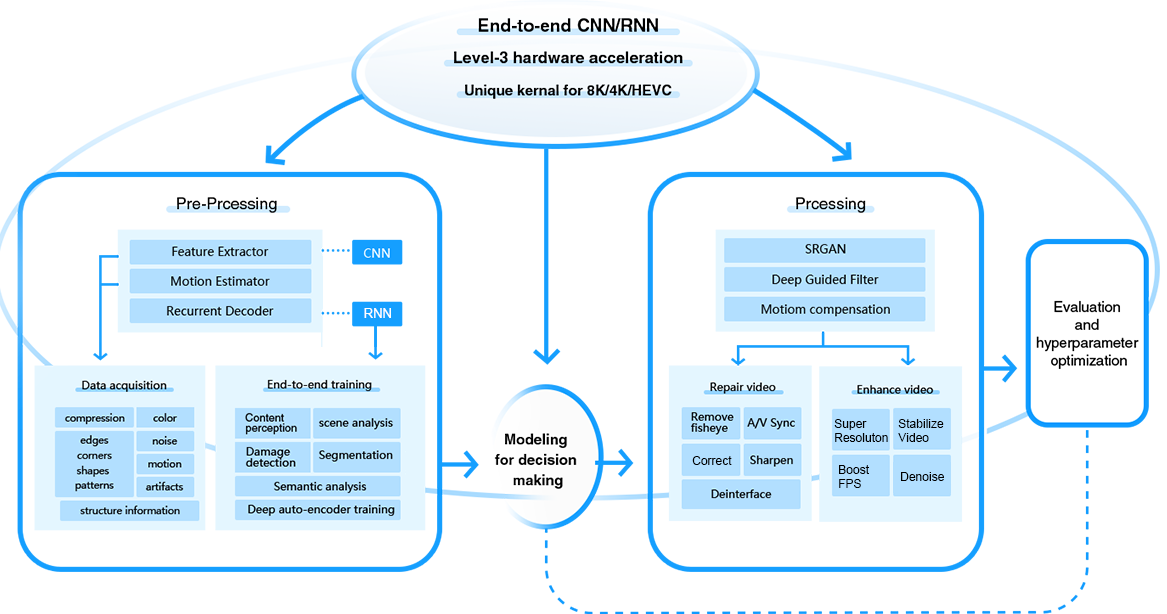
Codificador de extracción de características: una arquitectura de red neuronal convolucional (CNN) extrae hábilmente bordes, formas, texturas, información estructural, ruido, brillo, artefactos de compresión y movimiento. , y más. Al recopilar estas características de su conjunto de datos, el modelo se entrena para distinguir una calidad de vídeo superior.
Decodificador recurrente: esta estructura de autoaprendizaje, integrada con la red neuronal recurrente (RNN), realiza un análisis iterativo dentro de una transmisión de video. El análisis de escenas, el reconocimiento de contenidos, la segmentación semántica, la clasificación y otras operaciones facilitan la identificación de información esencial, refinando aún más la comprensión del modelo.
Filtro guiado profundo (DGF): el módulo determina la intrincada relación de mapeo entre la guía y los videos de entrada. Las correlaciones espaciales y los datos estructurales se fusionan a partir de imágenes de referencia para preservar los detalles y los bordes de la imagen, lo que culmina en una salida mejorada y sin ruido.
SRGAN: Al emplear una red neuronal de doble componente, SRGAN aumenta la resolución de vídeo a través de una arquitectura de bloques residuales. El entrenamiento adversario con un modelo discriminador evalúa la calidad frente a contrapartes reales de alta resolución, elaborando progresivamente resultados notables a través de la combinación de redes generativas adversarias y pérdida de percepción.
MEMC: rastrea fotogramas adyacentes dentro de un vídeo para inferir trayectorias de movimiento intrincadas de objetos dinámicos, como traslación, rotación y escalado. Esto permite contextualizar la optimización del vídeo. Basándose en la estimación del movimiento, la compensación de movimiento posterior rectifica la alineación de cada cuadro haciendo coincidir el cuadro anterior con el actual, para contrarrestar los desplazamientos reales inducidos por el movimiento. Esto reduce problemas como la inestabilidad, la borrosidad y la discontinuidad de los fotogramas y, en última instancia, crea un vídeo con mayor estabilidad, fluidez y lucidez cristalina.

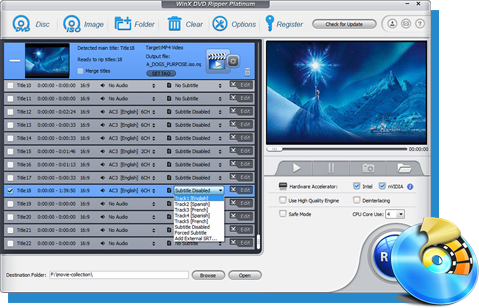












 Súper resolución de IA
Súper resolución de IA Estabilización de IA
Estabilización de IA Interpolación de IA
Interpolación de IA