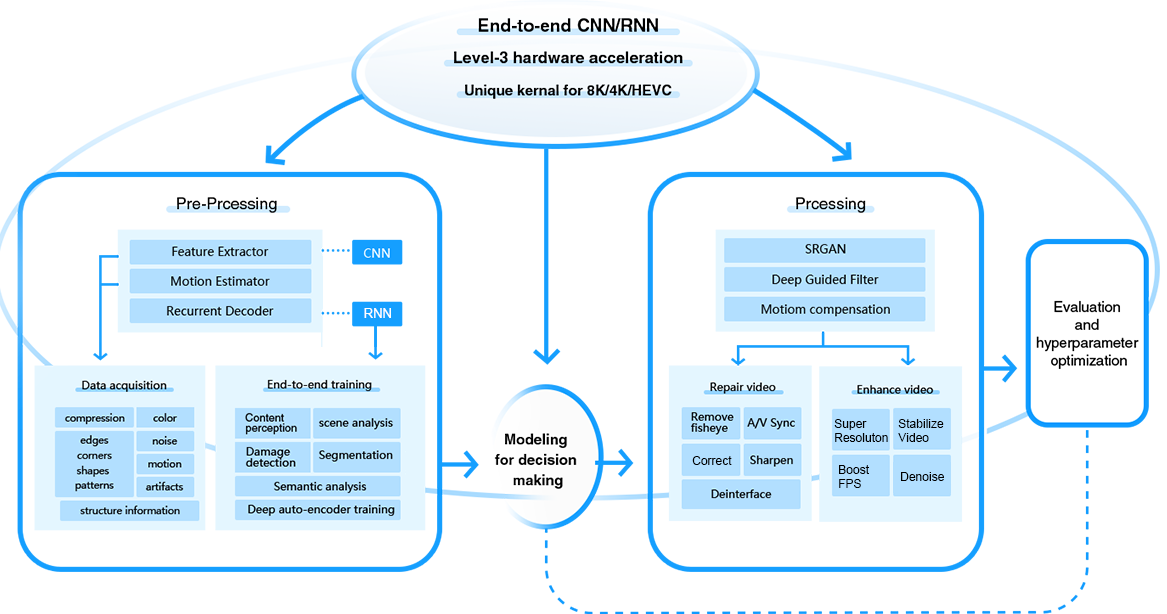
Merkmal-Extraktions-Encoder: Eine Convolutional Neural Network (CNN)-Architektur extrahiert geschickt Kanten, Formen, Texturen, Strukturinformationen, Rauschen, Helligkeit, Kompressionsartefakte, Bewegung und mehr. Durch das Sammeln dieser Merkmale aus ihrem Datensatz wird das Modell darauf trainiert, überlegene Videoqualität zu unterscheiden.
Rekurrenter Decoder: Diese selbstlernende Struktur, integriert mit Recurrent Neural Network (RNN), führt iterative Analysen innerhalb eines Videostreams durch. Szenenanalyse, Inhaltsidentifikation, semantische Segmentierung, Klassifizierung und andere Operationen erleichtern die Identifizierung wesentlicher Informationen und verfeinern weiter das Verständnis des Modells.
Deep Guided Filter (DGF): Das Modul stellt die komplexe Zuordnungsbeziehung zwischen Leitbildern und Eingabevideos sicher. Raumkorrelationen und Strukturdaten werden aus Referenzbildern verschmolzen, um Bilddetails und Kanten zu erhalten, was in einer rauschfreien und verbesserten Ausgabe resultiert.
SRGAN: Durch den Einsatz eines zweikomponentigen neuronalen Netzwerks erhöht SRGAN die Auflösung von Videos durch eine Residualblock-Architektur. Das adversarielle Training mit einem Diskriminator-Modell bewertet die Qualität im Vergleich zu tatsächlichen hochauflösenden Gegenstücken und erzeugt fortschrittlich bemerkenswerte Ausgaben durch die Kombination von generativen adversariellen Netzwerken und wahrgenommener Verlust.
MEMC: Es verfolgt benachbarte Frames innerhalb eines Videos, um die komplexe Bewegungsbahn dynamischer Objekte wie Translation, Rotation und Skalierung zu erschließen. Dies ermöglicht die Kontextualisierung der Videooptimierung. Basierend auf der Bewegungsschätzung korrigiert die nachfolgende Bewegungskompensation die Ausrichtung jedes Rahmens, indem der vorherige Frame mit dem aktuellen abgeglichen wird, um tatsächlich bewegungsbedingte Versätze auszugleichen. Dies reduziert Probleme wie Zittern, Unschärfe und Frame-Unstetigkeit und schafft letztendlich ein Video mit verbesserter Stabilität, Fluidität und kristallklarer Klarheit.

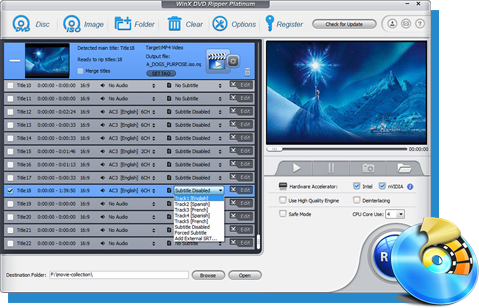












 AI Super Auflösung
AI Super Auflösung AI Videostabilisierung
AI Videostabilisierung AI Frame-Interpolation
AI Frame-Interpolation