Encodeur d'extraction de caractéristiques : Une architecture de réseau neuronal convolutif (CNN) extrait habilement les contours, les formes, les textures, les informations structurales, le bruit, la luminosité, les artefacts de compression, le mouvement, et plus encore. En collectant ces caractéristiques à partir de son jeu de données, le modèle est entraîné à distinguer une qualité vidéo supérieure.
Décodeur récurrent : Cette structure auto-apprenante, intégrée à un réseau neuronal récurrent (RNN), s'engage dans une analyse itérative au sein d'un flux vidéo. L'analyse de scène, la reconnaissance de contenu, la segmentation sémantique, la classification et d'autres opérations facilitent l'identification d'informations essentielles, affinant davantage la compréhension du modèle.
Filtre Guidé Profond (DGF) : Le module détermine la relation de cartographie complexe entre le guidage et les vidéos d'entrée. Les corrélations spatiales et les données structurelles sont fusionnées à partir d'images de référence pour préserver les détails et les contours de l'image, aboutissant à une sortie débruitée et améliorée.
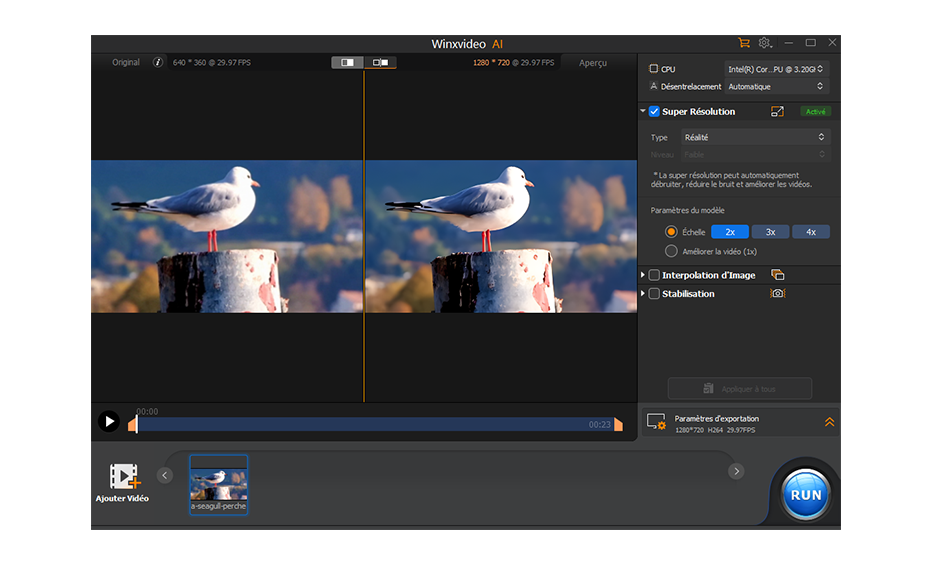
SRGAN : En utilisant un réseau neuronal à double composant, le SRGAN augmente la résolution vidéo grâce à une architecture de blocs résiduels. L'entraînement adversarial avec un modèle de discriminateur évalue la qualité par rapport à des contreparties haute résolution réelles, élaborant progressivement des sorties remarquables grâce à la combinaison de réseaux antagonistes génératifs et de pertes perceptuelles.
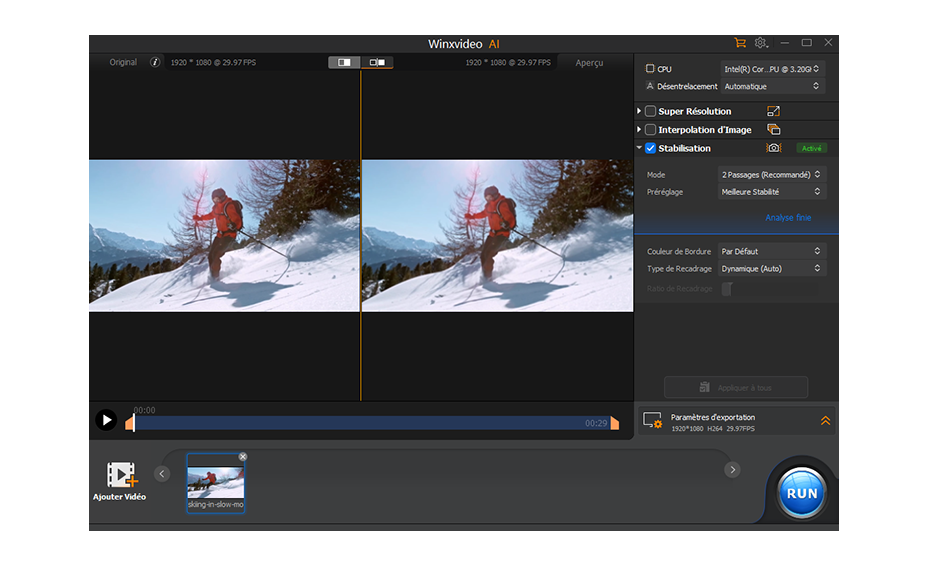
MEMC : Il suit les trames adjacentes d'une vidéo pour déduire la trajectoire de mouvement complexe des objets dynamiques, tels que la translation, la rotation et l'échelle. Cela permet de contextualiser l'optimisation vidéo. Basée sur l'estimation de mouvement, la compensation de mouvement subséquente rectifie l'alignement de chaque trame en faisant correspondre la trame précédente avec la trame actuelle, afin de contrer les décalages réels dus au mouvement. Cela réduit les problèmes tels que les saccades, le flou et les discontinuités de trame, créant finalement une vidéo d'une stabilité améliorée, d'une fluidité et d'une clarté cristalline.













 IA amélioration
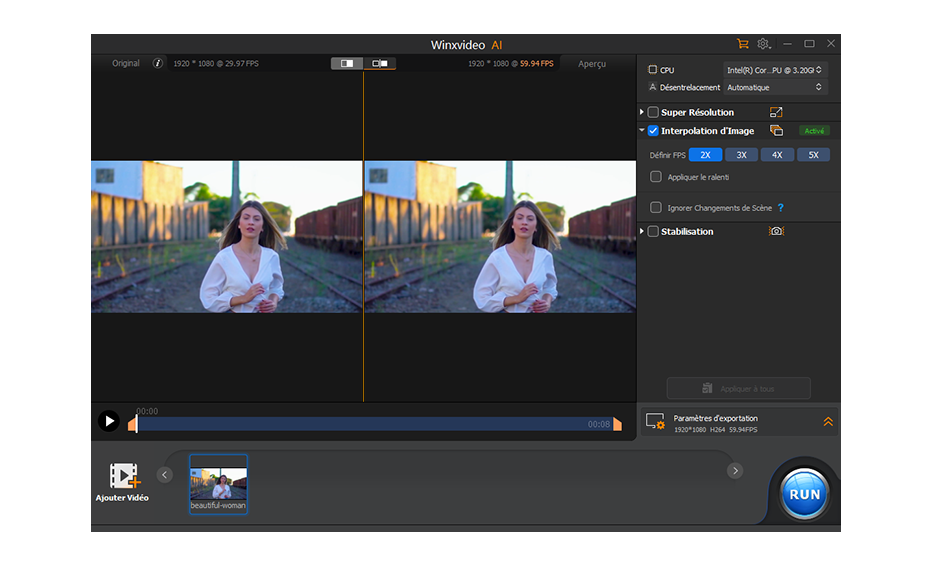
IA amélioration Stabilisation par IA
Stabilisation par IA  Interpolation IA
Interpolation IA